Uno de los problemas más frustrantes que me he encontrado a la hora de trabajar en algún proyecto que presente un mayor enfoque en los algoritmos, especialmente aquellos que involucran alguna forma de inteligencia artificial, es que el lenguaje en el que trabajas parece interponerse en tu camino. Cuando diseñas un sistema complejo desde el punto de vista de arquitectura de software los objetos y las clases te proporcionan una ayuda invaluable para su organización, si estas diseñando una web tienes lenguajes específicos que te ayudan a estructurar su estética, incluso cuando programas a bajo nivel dispones de herramientas que te proporcionan un control total sobre la máquina y, si es posible, te ayudan a que no metas mucho la pata.
Sin embargo parece que al trabajar con IA debemos escoger el lenguaje menos malo. Python parece un buen candidato y en efecto muchos lo usan, es agradable y no se mete mucho en tu camino, sin embargo esto es a costa de un buen rendimiento y de la corrección que proporciona un sistema de tipos. Con Java tienes esto último, pero introduciendo una cantidad de papeleo inmensa para hacer lo más básico, lo cual no es muy agradable si lo único que quieres es centrarte en tus algoritmos. Por último, si necesitas velocidad podrías decidirte por C++, en este caso te dará más problemas el manejo de memoria que la lógica del propio programa. No he puesto estos lenguajes como ejemplo de forma arbitraria, sino que son considerados como algunos de los mejores lenguajes para IA, creo que simplemente esto debería poner de relieve el problema.
En esta entrada recopilaré las características que harían de un lenguaje una herramienta óptima para codificar los problemas a los que se enfrenta la inteligencia artificial. Seguramente la solución que obtenga no sea ni mucho menos la mejor, tampoco lo pretendo, me conformo con poder aportar alguna idea interesante.
¿Tiene sentido un lenguaje orientado a la inteligencia artificial?
¿Por qué diseñar un lenguaje especifico para inteligencia artificial? ¿Se gana algo frente a los lenguajes ya existentes?
Uno de los argumentos más contundentes en contra de un lenguaje para IA es que, de hecho, no puede existir, el campo es muy poco definido, utiliza muchas técnicas diferentes y evoluciona demasiado rápido. La mejor aproximación no pasaría por crear un lenguaje específico sino por implementar librerías de calidad para cada caso. Mi respuesta es que esto no explica el porqué algunos lenguajes son más usados que otros en IA y las librerías especializadas parecen acumularse en estos mientras que otros carecen de ellas. Pareciera que hay elementos que hacen de algunos entornos especialmente atractivos para la implementación de algoritmos de inteligencia artificial.
Desafortunadamente no he encontrado ningún estudio al respecto, así que me he apañado un script en Python para sacar los datos de GitHub. Primero vamos a ver en que lenguajes están escritos los 500 repositorios más populares (con más estrellas) que aparecen en GitHub al buscar “artificial intelligence”:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import itertools
import time
from github import Github
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
# Devuelve un diccionario que asocia a cada lenguaje su número de repositorios
def count_repos_by_lang(repos):
repos_by_lang = {}
for repo in repos:
lang = repo.language
if lang is None:
continue
# Si el lenguaje principal es Jupyter Notebook utilizamos el segundo más usado
if lang == 'Jupyter Notebook':
languages = repo.get_languages()
# En caso de que el único lenguaje sea Jupyter Notebook
if len(languages) == 1:
continue
lang = sorted(languages, key=languages.get, reverse=True)[1]
repos_by_lang[lang] = repos_by_lang.get(lang, 0) + 1
return repos_by_lang
# Iniciamos sesión en GitHub
g = Github("usuario", "contraseña")
# Obtenemos los 500 repositorios más populares en inteligencia artificial
ai_repos = itertools.islice(g.search_repositories("artificial intelligence", sort="stars"), 500)
ai_repos_by_lang = count_repos_by_lang(ai_repos)
# Los disponemos en una gráfica
plt.bar(list(ai_repos_by_lang.keys()), list(ai_repos_by_lang.values()), color=(0.16, 0.5, 0.73, 1))
plt.xticks(rotation=90, fontsize='8')
plt.yticks(fontsize='8')
plt.subplots_adjust(bottom=0.2)
plt.show()
Estos son los resultados que obtenemos:
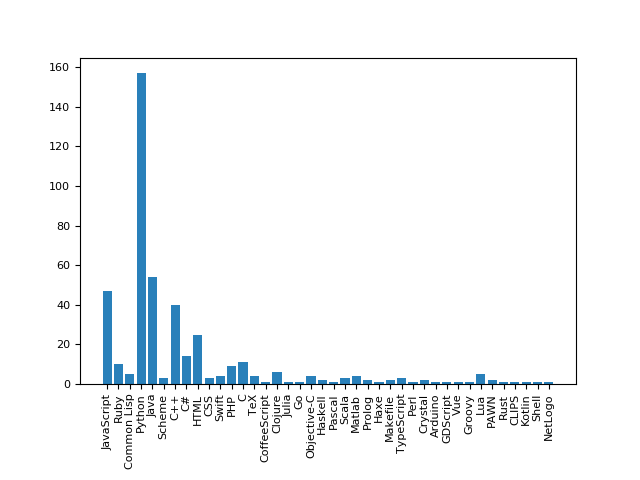
A priori parece que es cierto que hay lenguajes que destacan más en el campo de la inteligencia artificial, pero cabe la posibilidad de que estos datos simplemente reflejen la popularidad de cada lenguaje. Para descartar esto obtendremos los 500 repositorios más populares de GitHub y calcularemos el ratio de uso en IA frente al uso general de cada lenguaje:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# Obtenemos los 500 repositorios más populares de GitHub
popular_repos = itertools.islice(g.search_repositories("stars:>1", sort="stars"), 500)
popular_repos_by_lang = count_repos_by_lang(popular_repos)
# Calculamos el ratio de uso de cada lenguaje en proyectos de ia y en general
proportion_by_lang = {}
for lang in ai_repos_by_lang.keys():
proportion_by_lang[lang] = ai_repos_by_lang[lang] / popular_repos_by_lang.get(lang, -1)
# Lo disponemos en una gráfica
plt.axes().yaxis.set_minor_locator(ticker.MultipleLocator(1))
plt.axhline(y=0, linewidth=0.75, color=(0.27, 0.27, 0.27))
plt.axhline(y=1, linewidth=0.35, color=(0.27, 0.27, 0.27))
plt.bar(list(proportion_by_lang.keys()), list(proportion_by_lang.values()), color=(0.16, 0.5, 0.73, 1))
plt.xticks(rotation=90, fontsize='8')
plt.yticks(fontsize='8')
plt.subplots_adjust(bottom=0.2)
plt.show()
Notar que si un lenguaje se ha usado en proyectos de IA pero no en proyectos generales el ratio sería infinito, en este caso le asignaremos como valor el número de repositorios de IA en el que se usa pero en negativo, para que no haya confusión. Teniendo esto en cuenta los resultados quedan así:
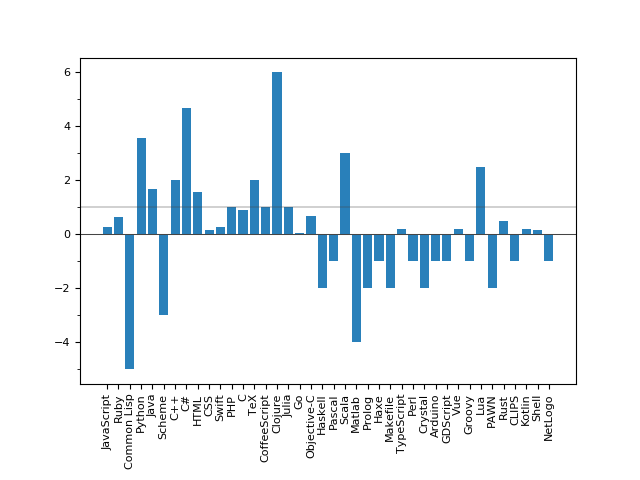
Los lenguajes con un ratio menor que 1 son menos usados en IA que en otro tipo de proyectos y viceversa. Esto claramente no es un estudio serio, tiene un montón de fallas que pueden arrojar datos imprecisos, por ejemplo depende de lo que GitHub entienda como “artificial intelligence” en su búsqueda. Además los ratios de algunos lenguajes pueden explicarse por sus particularidades, por ejemplo HTML y CSS, siendo lenguajes específicos del diseño web, es esperable que no puntúen muy bien. Sin embargo creo que cumple con la intención de señalar que realmente hay lenguajes que atraen a los desarrolladores de IA más que otros. Entonces cabe preguntarse ¿por qué? Estas diferencias pueden deberse a múltiples factores: librerías, comunidad, soporte de herramientas (e.g. debuggers, gestores de paquetes), tradición, etc. Sin embargo estos elementos tienen que formarse al rededor de un lenguaje, por lo tanto este tiene que ofrecer un potencial que otros no, pero además esto nos lleva a otro punto a favor de un lenguaje especializado en IA.
Que un lenguaje esté especializado en inteligencia artificial no solo significa que adapte su sintaxis o que tenga determinados constructos semánticos especialmente útiles (lo cual no es poca cosa), significa que gran parte del esfuerzo estará dirigido a tener un entorno lo más adaptado posible. Significa que se podrán invertir recursos en tener las mejores librerías de NPL, ML, planificación, estadística, etc posibles. Que las herramientas tales como debuggers estarán pensadas especialmente para resolver los problemas que plantee este campo sin dividir recursos en las necesidades que puedan surgir de, por ejemplo, la programación web o la de sistemas. También quiere decir que todas estas herramientas y librerías podrían estar al día de los últimos avances en investigación. En definitiva, una menor superficie nos permite enfocar mejor nuestros esfuerzos.
Ok, me has convencido, pero ¿cómo lo hacemos?
Que un lenguaje para IA tenga sentido no quiere decir que las objeciones planteadas arriba estén erradas, ciertamente el hecho de que la inteligencia artificial como campo esté muy pobremente definido y que se mueva muy rápido plantea muchas dificultades.
Por estas razones no es factible que este lenguaje sea un DSL, como podría serlo uno orientado a un dominio más concreto (e.g. Prolog en programación lógica), sino que deberá ser un lenguaje de propósito general, pero con ciertas características especialmente convenientes. El ejemplo más próximo sería trasladar lo que ha hecho Julia en el área de la computación numérica a la inteligencia artificial. Para extraer estas características primero debemos conocer las necesidades más habituales a la hora de implementar una IA.
Peculiaridades de la inteligencia artificial como ingeniería de software
Günter Neumann rescata ciertos elementos que diferencian el trabajo en inteligencia artificial del de otras áreas y que explicarían porqué Lisp y Prolog han sido lenguajes tan relevantes en este campo:
-
La IA se centra en la computación simbólica más que en el procesamiento de números, siendo especialmente adecuados para el manejo de símbolos los lenguajes declarativos.
-
La especificación inicial de un problema de IA es compleja, es más eficaz desarrollar los algoritmos de forma gradual mediante prototipos.
-
Los algoritmos de IA no requieren de un control total de la máquina, por lo que es beneficioso un mayor nivel de abstracción que libere al programador de detalles de bajo nivel como el manejo de memoria.
Aunque algunos de estos puntos ya han sido superados y los vemos como normales en los lenguajes actuales (incluso se podría discutir el primero dada la importancia de la estadística en la IA moderna), hay que tener en cuenta que antes de que Lisp introdujese avances como la recolección de basura lo mejor que se tenía era Fortran, que se especializaba en el puro procesamiento numérico.
Me permitiré añadir otros factores que, basándome el lo que conocemos sobre la inteligencia y por experiencia personal, en mi opinión también caracterizan al campo:
-
Mayor énfasis en los algoritmos que en el diseño de software.
-
Ejecuciones largas, se necesita algún mecanismo que asegure que el programa no va a fallar después de varias horas de ejecución por escribir mal el nombre de una variable.
-
Consumo de recursos considerable
-
Uso de herramientas lógicas y estadísticas, siendo particularmente útil la capacidad de codificar objetivos y modelos del mundo.
-
Frecuente manejo de diferentes estructuras de datos.
-
Concurrencia. Muchos de nuestros procesos mentales ocurren en paralelo.
-
Necesidad de feedback continuo. Esto ayuda en el proceso de ensayo y error que supone calibrar un algoritmo.
-
Visualización y comparación de resultados.
-
Diseño modular que facilite la integración de distintas herramientas de forma organizada.
Creo que un lenguaje que de respuesta a estas particularidades es un buen candidato para ser usado en IA más allá de las diferentes modas que puedan sucederse.
Aspectos principales de nuestro lenguaje
Intentemos esbozar los principales componentes de un lenguaje pensando en dar solución a los puntos anteriores.
Me parece buena idea establecer una lista de prioridades en características que puedan estar en conflicto. Esto permite simplificar la elección de introducir o no un elemento que requiere un trade-off entre alguna de estas, basta ver si la característica que se beneficia tiene más prioridad que la que sale perjudicada.
Para este caso la siguiente lista me parece razonable:
-
Velocidad de implementación, testeo y cambio
-
Eficiencia
-
Capacidad de aumentar el lenguaje
-
Corrección de los programas
Runtime
Sistema de traducción: Compilado AOT vs Interpretado vs JIT
Veamos las ventajas e inconvenientes de cada uno de los tipos.
Compilación AOT:
- + Produce código muy eficiente.
- + Solo pasa por el proceso de traducción una vez.
- + Quien recibe el ejecutable no necesita tener un compilador instalado.
- - Cada vez que se quiera probar un cambio hay que volver a compilar. Puede paliarse con un buen sistema de compilación.
Interpretación:
- + Mayor flexibilidad (e.g. pueden modificarse a si mismos en tiempo de ejecución).
- + No hay que compilar cada cambio.
- - Tiene más limitaciones a la hora de hacer eficiente el código.
- - Pasa por el proceso de traducción cada vez que se ejecuta el programa.
Compilación JIT:
- + Mantiene todas las ventajas de la interpretación.
- + La eficiencia es cercana a la de la compilación AOT, incluso en algunos casos puede hacer optimizaciones específicas con los datos de la ejecución actual y los del entorno donde se ejecuta.
- - La compilación se realiza en cada ejecución.
- - Algunas optimizaciones que realizaría un compilador AOT son demasiado costosas para ser hechas en tiempo de ejecución.
- - Complicado de implementar comparado con la interpretación y la compilación AOT.
En mi opinión, el sistema que mejor cumple nuestros requisitos sería un compilador JIT con opción de compilación AOT. De esta forma conseguimos un workflow ágil con bastante eficiencia y en caso de que el overhead del JIT no sea aceptable o se necesite un ejecutable independiente se podría compilar AOT.
La principal desventaja sería la dificultad de implementación, que ya de por sí es elevada con un solo traductor (sobre todo en el caso de un JIT).
Manejo de memoria: manual vs GC vs Ownership
Manual:
- + Control total sobre la memoria. Lo que permite programas más eficientes.
- - El programador debe razonar sobre la memoria, lo cual consume “espacio cognitivo” para pensar en los algoritmos.
- - Es un sistema propenso a fallos que además no pueden detectarse en tiempo de compilación (El lenguaje no es seguro).
GC:
- + El programador se despreocupa del manejo de la memoria.
- + Permite lenguajes seguros.
- - Añade overhead a la ejecución.
- - Aumenta la complejidad del compilador.
Ownership (tipo Rust):
- + Permite lenguajes seguros, los fallos de memoria se detectan en tiempo de compilación.
- + No añade overhead.
- - El programador sigue teniendo que razonar sobre la memoria, además con restricciones sobre su uso.
Dado que tanto el manejo manual como el ownership distraen al programador de su tarea principal y dificultan el realizar cambios en el código, siguiendo nuestra lista de prioridades la única opción factible que nos queda es usar un recolector de basura.
Sistema de tipos
La primera elección que tenemos que tomar claramente es si queremos un sistema de tipos, es decir, si nuestro lenguaje va a ser débilmente o fuertemente tipado.
Un sistema débil proporciona más flexibilidad y rapidez en la implementación, pero uno fuerte da herramientas para asegurar cierto buen comportamiento de los programas y la información extra puede aprovecharse para generar código más eficiente.
Por suerte existe una forma de obtener las ventajas de ambos sistemas, el tipado gradual (gradual typing). Un lenguaje con este sistema permitiría prototipados que pueden cambiarse rápidamente y una vez que se ha llegado a una versión definitiva poder garantizar cierta corrección. Me parece el sistema ideal a la hora de trabajar en algoritmos de inteligencia artificial.
Un sistema de tipos que parece complementarse especialmente bien con el tipado gradual es la unión e intersección de tipos, pero tengo que investigar más al respecto.
Concurrencia
La capacidad de paralelizar código es crucial en el ámbito de la IA, no solo porque permite disminuir el tiempo de ejecución de los programas, sino porque es muy posible que la inteligencia real esté constituida de muchos procesos que trabajan a la vez, en palabras de Marvin Minsky “la mente es una sociedad de agentes”.
Siguiendo el razonamiento de liberar al programador de carga extra en la medida de lo posible, los sistemas de memoria compartida mediante mutex o semáforos quedan descartados. Esto nos deja con un sistema de paso de mensajes, mucho más simple y seguro.
En este aspecto me parece interesante la programación concurrente tipada (Session-Types), especialmente diseñada para paso de mensajes y que podría añadir una capa más de corrección al código. Sin embargo, como cualquier otro sistema de tipos, también resta flexibilidad y no se si se han hecho esfuerzos por crear session-types graduales.